时间: 2026-01-03 20:53:10 人气: -
码执行效果:
仅供研究学习phthon代码,不做其它用途。
代码思路:
以前借鉴其它同学的代码,发现下载小说时总是会出现各种问题。
主要解决两大问题:
一是避开网站的反爬虫机制,采用单线程下载。
二是适用于单章节分两页的小说站。
创新点:
一是重试机制采取多轮重试,从第二轮开始只重试下载失败的章节。
二是针对小说内容写在p标签和不在p标签中的分别进行了处理,代码稍加修改即可适用于大多数同类型的小说站。
import os
import re
import random
import time
import requests
from lxml import etree
from requests.adapters import HTTPAdapter
import chardet
# 用户代理列表
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
]
# 设置连接池大小并设置重定向限制
session = requests.Session()
adapter = HTTPAdapter(pool_connections=100, pool_maxsize=100, max_retries=5) # 设置连接池大小为100
session.mount('http://', adapter)
session.mount('https://', adapter)
session.max_redirects = 300 # 设置最大重定向次数为300
def get_chaptercontent(chapter_url, temp_file, queue, semaphore, session):
"""下载单个章节内容,只尝试一次,同时要处理有一章内容分两页的情况"""
try:
time.sleep(3) # 增加请求间隔,避免被封
headers = {
'User-Agent': random.choice(user_agents),
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://www.baiduxs.com'
}
# 尝试获取章节内容
response = session.get(chapter_url, headers=headers, timeout=50)
response.raise_for_status() # 如果请求失败会抛出异常
# 检查页面是否完整加载
raw_data = response.content
detected = chardet.detect(raw_data)
encoding = detected['encoding'] if detected['encoding'] else 'utf-8'
html = raw_data.decode(encoding, errors='replace')
# 检查是否有章节内容
if '<div id="content">' not in html:
print(f"页面内容不完整: {chapter_url}")
if queue:
queue.put(None)
return False
selector = etree.HTML(html)
chapter_title = selector.xpath('//h1/text()')
# 一般情况下的contents下面是p标签,但不一定都是这样,需要进行多种情况的判断
contents = selector.xpath('//div[@id="content"]/p/text()')
flag = False
# 有的内容是直接放在div下面,没有用p标签,所以用下面的代码处理
if not contents:
contents = selector.xpath('//div[@id="content"]/text()')
if contents and isinstance(contents, list): # 确保contents不为空且是list类型
flag = True
if not chapter_title or not contents:
print(f"未能找到章节内容: {chapter_url}")
if queue:
queue.put(None)
return False
# print(f'flag: {flag} 为True表明小说内容用的不是p标签')
# 开始处理一章分多页的情况
next_page = selector.xpath('//a[@id="A3"]/@href')[0]
# print(f'next_page: {next_page}')
# 取next_page的右边数12字符
char12 = next_page[-12:]
if char12.find("_") != -1: #网址中包含”_“,说明是单章分多页
next_page_url = f'{base_url}{next_page}'
# 尝试获取章节内容
response = session.get(next_page_url, headers=headers, timeout=60)
response.raise_for_status() # 如果请求失败会抛出异常
# 检查页面是否完整加载
raw_data = response.content
detected = chardet.detect(raw_data)
encoding = detected['encoding'] if detected['encoding'] else 'utf-8'
html = raw_data.decode(encoding, errors='replace')
# 检查是否有章节内容
if '<div id="content">' not in html:
print(f"第2页页面内容不完整: {chapter_url}")
if queue:
queue.put(None)
return False
selector = etree.HTML(html)
# 一般情况下的contents下面是p标签,但不一定都是这样,需要进行多种情况的判断
contents2 = selector.xpath('//div[@id="content"]/p/text()')
flag = False
if not contents2:
contents2 = selector.xpath('//div[@id="content"]/text()')
if contents2 and isinstance(contents2, list):
flag = True
if not contents2:
print(f"未能找到本章节第2页内容: {chapter_url}")
if queue:
queue.put(None)
return False
else:
# 把第二页内容合并到第一而内容中
print(" 发现本章节分两页,将合并到同一章节...")
contents.extend(contents2)
# 拼接章节内容
chapter_content = '\n'.join(content.strip() for content in contents if content.strip())
# 剔除掉contents中<style>与</style>之间的内容
chapter_content = re.sub(r'(?is)(?:<style.*?>.*?</style>|</style>)', '', chapter_content).strip()
# 下一句是把内容中的<br />或者<br>标签替换为换行
chapter_content = re.sub(r'<br />|<br>', '\n', chapter_content).strip()
chapter_content = re.sub(r'\n\n', '\n', chapter_content).strip()
# 把内容中的 换成空格
chapter_content = re.sub(r' ', '', chapter_content).strip()
chapter_title = chapter_title[0] # 假设只有一个标题
print(f"\t正在下载:{chapter_title}")
# 写入临时文件
with open(temp_file, 'w', encoding='utf-8') as f:
f.write(chapter_title + '\n\n')
f.write(chapter_content)
if queue:
queue.put(temp_file)
return True
except requests.exceptions.RequestException as e:
print(f"下载章节失败: {chapter_url} - 错误: {str(e)}")
if queue:
queue.put(None)
return False
except Exception as e:
print(f"处理章节时发生未知错误: {str(e)}")
if queue:
queue.put(None)
return False
def download_chapters(chapters_url):
try:
# 增加目录页加载等待
max_wait_attempts = 3
wait_attempt = 0
response = None
html = None
while wait_attempt < max_wait_attempts:
try:
response = session.get(chapters_url, headers={'User-Agent': random.choice(user_agents)}, timeout=30)
# 使用lxml解析响应文本
raw_data = response.content
detected = chardet.detect(raw_data)
encoding = detected['encoding'] if detected['encoding'] else 'utf-8'
html = raw_data.decode(encoding, errors='replace')
# 检查是否有章节列表
if '<div id="list">' in html:
break
wait_attempt += 1
if wait_attempt < max_wait_attempts:
print(f"目录页内容未完整加载,等待2秒后重试... (尝试 {wait_attempt}/{max_wait_attempts})")
time.sleep(2)
response.close()
continue
except requests.exceptions.RequestException as e:
wait_attempt += 1
if wait_attempt < max_wait_attempts:
print(f"请求失败,等待2秒后重试... (尝试 {wait_attempt}/{max_wait_attempts})")
time.sleep(2)
if 'response' in locals():
response.close()
continue
else:
raise e
response.close() # 确保连接关闭
if response.status_code != 200:
print(f"未能获取URL: {response.status_code}")
return
if not html:
print(f"未能获取URL: {response.status_code}")
return
else:
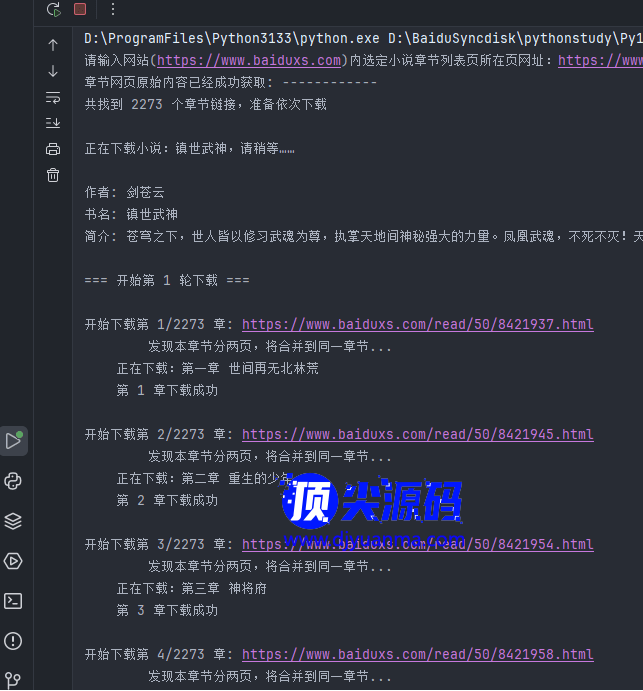
print("章节网页原始内容已经成功获取: ------------")
selector = etree.HTML(html)
chapter_links = selector.xpath('//div[@id="list"]/dl/dd/a/@href')
if not chapter_links:
print("未找到章节链接。")
return
# 去除前12个最新更新章节,这样可以得到从第一章开始的章节,避免重复
if len(chapter_links) >= 13:
chapter_links = chapter_links[12:]
print(f"共找到 {len(chapter_links)} 个章节链接,准备依次下载")
# 获取书籍名称
book_name = selector.xpath('//h1/text()')[0]
if not book_name:
print("无法获取书名。")
return
# 从页面头部的<meta property="og:novel:author" content="魔性沧月"/>中获取作者
book_author = selector.xpath('//meta[@property="og:novel:author"]/@content')[0]
if not book_author:
book_author = "未知"
book_intro_list = selector.xpath('//div[@id="intro"]/p/text()')
book_intro = ''.join(book_intro for book_intro in book_intro_list if book_intro.strip())
if not book_intro:
book_intro = "无简介"
print(f'\n正在下载小说:{book_name},请稍等……\n')
# 将作者、书名和简介打印出来
print(f"作者: {book_author}\n书名: {book_name}\n简介: {book_intro}")
# 保存目录
save_directory = os.path.join(os.environ["USERPROFILE"], 'Downloads', 'mybooks')
os.makedirs(save_directory, exist_ok=True) # 创建保存目录
# 初始化失败章节列表
failed_chapters = []
for index, href in enumerate(chapter_links):
failed_chapters.append({
'index': index,
'href': href,
'retry_count': 0
})
# 最多下载5轮。第一轮正常下载,失败的章节会加入列表,待下一轮专门下载失败的章节,直到全部下载成功或重试次数达到上限。
max_download_times = 5
retry_round = 0
temp_files = []
while retry_round < max_download_times and len(failed_chapters) > 0:
retry_round += 1
print(f"\n=== 开始第 {retry_round} 轮下载 ===")
current_failed = []
for chapter in failed_chapters:
index = chapter['index']
href = chapter['href']
# 拼成完整域名
chapter_url = f'{base_url}{href}'
temp_file = os.path.join(save_directory, f'temp_{index:04d}.txt')
print(f"\n开始下载第 {index + 1}/{len(chapter_links)} 章: {chapter_url}")
try:
success = get_chaptercontent(chapter_url, temp_file, None, None, session)
if success and os.path.exists(temp_file) and os.path.getsize(temp_file) > 0:
temp_files.append(temp_file)
print(f" 第 {index + 1} 章下载成功")
else:
print(f" 第 {index + 1} 章下载失败")
chapter['retry_count'] += 1
current_failed.append(chapter)
except Exception as e:
print(f"下载第 {index + 1} 章时发生错误: {str(e)}")
chapter['retry_count'] += 1
current_failed.append(chapter)
failed_chapters = current_failed
if len(failed_chapters) > 0 and retry_round < max_download_times:
print(f"\n本轮下载完成,{len(failed_chapters)} 章下载失败,将在下一轮重试...")
time.sleep(5) # 等待5秒后重试
# 合并临时文件到主文件
append_temp_files_to_main(temp_files, save_directory, book_name, book_author, book_intro)
print(f"\n小说《{book_name}》下载完成,共下载 {len(temp_files)}/{len(chapter_links)} 章")
if len(failed_chapters) > 0:
print(f"以下章节下载失败: {[chap['index']+1 for chap in failed_chapters]}")
except requests.exceptions.RequestException as e:
print(f"获取章节列表时发生错误: {str(e)}")
return
except Exception as e:
print(f"处理章节时发生未知错误: {str(e)}")
return
def append_temp_files_to_main(temp_files, save_directory, book_name, book_author, book_intro):
book_path = os.path.join(save_directory, f'{book_name}-{book_author}.txt')
with open(book_path, 'w', encoding='utf-8') as main_file:
main_file.write(f'书名:《{book_name}》\n作者:{book_author}\n简介:{book_intro}\n\n')
for temp_file in temp_files:
with open(temp_file, 'r', encoding='utf-8') as tf:
chapter_text = tf.read().strip()
if chapter_text: # 确保章节文本非空
main_file.write(chapter_text + '\n\n')
os.remove(temp_file) # 删除临时文件
if __name__ == "__main__":
base_url = 'https://www.baiduxs.com'
url = input(f"请输入网站({base_url})内选定小说章节列表页所在页网址:")
if url == '':
url = 'https://www.baiduxs.com/read/84347/'
print(f'你没有输入网址,默认以{url}《玩转大唐》为例进行下载……')
while not url.startswith(base_url):
print(f" 输入错误! 网址必须以{base_url}开头")
url = input(f"请输入网站({base_url})内选定小说章节列表页所在页网址:")
start_time = time.time()
download_chapters(url)
end_time = time.time()
print(f'\n总耗时:{end_time - start_time:.2f}秒。\n')
input("下载完成,小说保存在{用户}/Downloads/mybooks文件夹内,回车退出!")
本人也是Python的初学者,代码有不足之处,敬请各位大神批评指正
上一篇: DIV+CSS规范命名集合
下一篇: JS+CSS实现指定日期全站变灰